



Welcome to a new B4DS notebook!! In this article we wish to introduce the PRELEARN https://sites.google.com/view/prelearn20/home challenge. It was part of EVALITA 2020, https://www.evalita.it/2020 a workshop holding several Natural Language Processing tasks in Italian. Natural Language Processing is the extraction of relevant information analysing the human language in written form (natural language, in jargon) in automatically way.
The proliferation of e-learning platforms, electronic textbooks and educational applications has shed light on the need of developing systems able to identify educational relations between learning concepts for developing automatic tools that aims to support both students and teachers in the next generation of learning. Establishing the prerequisite relations for a given subject matter is one of the most educational challenge since these relations define which sequence of concepts allows students to have a full comprehensive of the subject. The need of inferring prerequisite relations from educational texts inspired PRELEARN to challenge scientists, mostly Italians in this case, as you could guess from the name (evalITA).
PRELEARN community provides the participant of a dataset and a task. An example of the task could be “Classify an English text according to the nationality of the writer”. Then, a challenge is open for attempting to solve the task. The participants are ranked based on how well they managed to perform. We participated at the PRELEARN challenge, where we positioned 2nd!!
The dataset in this case, is a number of pairs of Wikipedia pages, and the task consists
in:
“Finding out when two concepts are one a prerequisite of the other”

For example, in the above excerpt of the dataset we see that Terna Pitagorica (Pythagorean Triple) is a prerequisite of Spigolo (Edge), whereas Punto Medio (Middle Point) is not a prerequisite of Diagonale (Diagonal).
The pages provided as data are not randomly selected from Wikipedia, they are subdivided into 4 categories: Precalculus, Geometry, Physics and Data Science. How one tries to classify these concepts’ pairs depends entirely on their choice, however, who proposed the challenge needs a way to evaluate the results of each participant.
How does this happen?? The participants are provided with data, in this case text, and are given a labelled dataset, this means pairs of pages of which they already know if the first is a prerequisite of the second or not. Moreover, they are provided with a set of pairs, of which they don’t know the correctness whereas the authors do. To participate one needs to provide a classification of the unlabelled data. At the end those who proposed the challenge check how many one predicted correctly and this gives the ranking.
B4DS@PRELEARN
The B4DS team tackled this challenge with two distinct approaches, on one side we tried to make use of the page title, on the other we tried to leverage information present in the page body.
First Method
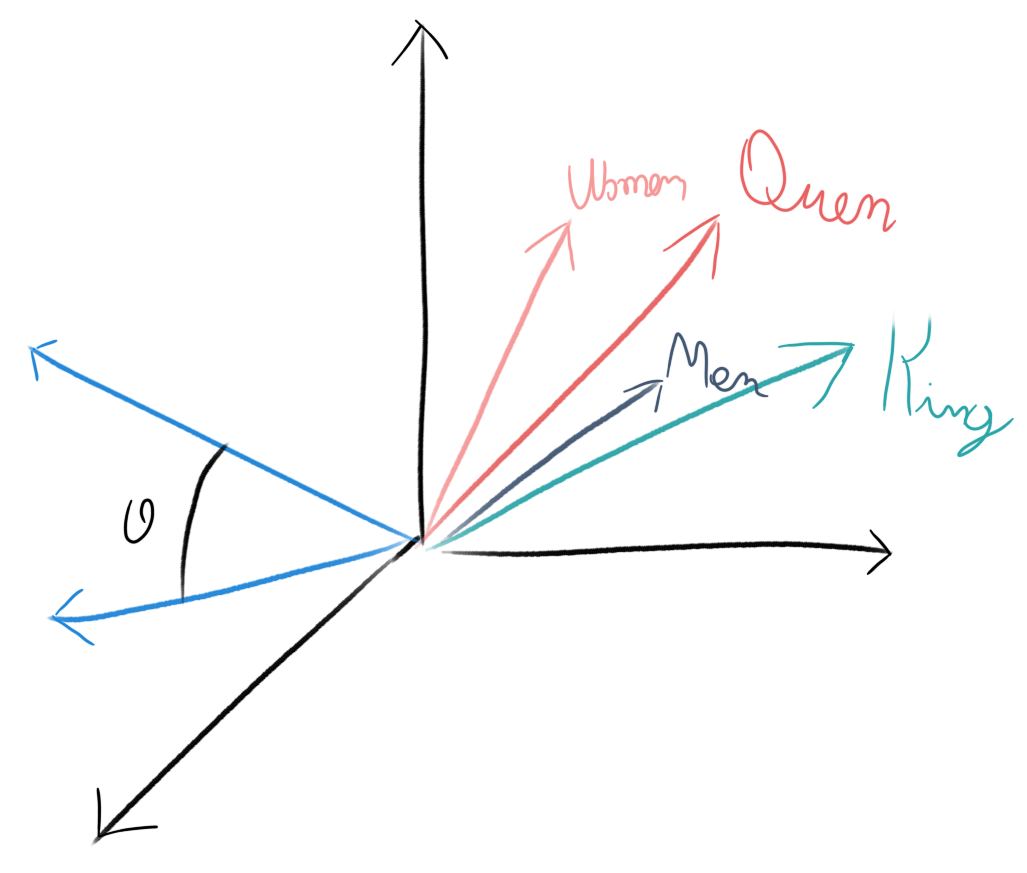
In the first case we used word embeddings, a statistical representation of text, extrapolated from other data, this means that a model is defined to approximate words with numbers. How is that possible?? It is indeed very difficult, the idea consists in trying to put in different points in space (vectors) each word, in a way that similar words, have similar vectors. In the image you can see that the vectors identifying King and Queen are close and those identifying Man and Woman are too. Moreover, in some cases we can use vectors geometrical properties to look for meaning. That is we might be able to find relations of this kind:
Queen = King – Man + Woman
Where the operations on the right side are actual arithmetic operations between vectors.
This is only possible by having a computer look at an incredibly large amount of text, however after this is done you can easily check which vector describes your words and then compare it to others. What we did is checking which representation (still a vector) is assigned to the words in the Wikipedia pages’ titles and then used an algorithm to try to identify which pairs represent a prerequisite and which do not. In our case the above equation would become:
Square = Triangle – three + four
Second Method
In the second case we trained a recurrent neural network on the pages’ own text (for further information on this topic see the Wikipedia page of the recurrent neural network[1]. Which are the perquisites of this topic? Try to discover it!). What did we do?? In a general sense what we did here is the opposite of what we did in the first method. There we gave each word a vector based on a model already created, here we had a computer look at all the text in the pages and tried to make a vector for each page. Why not use the same vectors as before?? If we make representations designed for this specific task they could be better when we use them to check if pairs are prerequisite or not. The downside of this approach is that while the embeddings we used before are created on a very large corpus (most of Italian Wikipedia), to create our own we only have the documents they gave us for this task. The vectors we obtained in this case are less precise, thus they do not let us understand a relation as complex as the one above, however for our task they provide more detailed information. A short note, one of the drawback of these vectors is that it is really hard to understand what they mean so while for simple cases as the ones above one can infer some significance, it is generally hard to find such clean examples.
Lesson Learned
The trait shared by both our approaches is the use of quantitative text analysis methodologies, namely Natural Language Processing methodologies, one of B4DS very specialties, more on this later!! While dealing with this task, we learned several things, first of all, we found out that the results on mathematics and physics are much better than those on the other two classes. We could conclude that computers have a harder time trying to classify geometry and data science instead of mathematics and physics which would definitely be an unexpected result. 😀😀😀
Jokes aside however, we can’t really accept this deduction from our analysis, though we did see the difference in performance on the datasets at hand. Indeed, as you learn working with data, caution is needed while generalizing results emerging from a single dataset. At B4DS we make no exception and we hold on to this principle, though it makes us a little sad that we can’t say data science is harder to study than mathematics.
Afterwards we analysed our models to see whether we could learn something from comparing their performances, and in this case too we made some interesting findings. We were able to see how the two approaches, though quite different, are very close in performance, that is, they correctly guessed a similar number of pairs. This is relevant since, as we described, we used representations built in very different ways, in other words with the second method we were able to create good vectors of our own, however not so good that they would serve us better than the general purpose one we used in the first method. Thus, we saw how in this project, like in any other involving the study of data through quantitative models, one has to take care of both data and models at once in order to be able to properly understand the results and draw exact conclusions.
Next Steps
Though one of our specialties is the quantitative analysis of texts, finding fields of application and challenges to keep testing the effectiveness of our methodologies and of our brains is not second to it, thus, as soon as we were done with PRELEARN, we asked ourselves where we could apply what we had learned on this occasion. If B4DS first nature is research, its second one is business creation and development, thus, instead of looking for mathematics and physics we moved towards this direction and we tried to perform similar analysis in the field of Marketing. Differently from what we had to do for the challenge, in this case we need to start from scratch, in particular nobody is providing us with a dataset, instead, we look for it ourselves. Where better than on the world wide web to look for things?? That’s where we started!!
B4DS in action
We started from PRELAEARN, a very specific challenge, with a clear focus on methodology, whereas now we move on to an application that is somewhere between methodology and content, indeed, although the quantitative analysis of text is fascinating, it’s what it allows us to find out what really interests B4DS. After a fair share of web-scraping and data collection we began to find something interesting. The first question we asked ourselves is:
“can we create a dataset similar to the one we were given during the challenge?”
This is still in progress. However we can provide some cliff-hangers to make you come back to read B4DS notebooks, let us show a first hint toward what we are trying to build. Looking at the image lets you guess what we are doing, we are building a map of concepts linked to Marketing!!! What we mean by linking concepts is exactly what we investigated for the challenge, which concepts are prerequisite to other in the marketing world?? Moreover, this image allows us to tell another one of the steps often showing up in our projects, data cleaning. As you can see, the data we have gathered so far are still partially dirty, there are some nodes in the image we would like to prune, being able to pinpoint those that look unfit for our task is our current goal. Though there are some clues that show we are moving in the right direction, we can’t stop to look at what we did yet. If we manage to proceed will be told in a new B4DS notebook, SEE YOU THEN!!!

In this Notebook we dealt with the two key parts any data science project revolves around, a deep analysis of data at hand and a careful choice of the models. In this case the results obtained, we positioned second in the challenge, and the analysis that accompanied them confirmed to us how these two steps are both necessary to face this type of problems. Indeed, focusing exclusively on models, disregarding data does not allow to choose the first appropriately, at the same time each dataset has a best suited model to investigate it and being able to choose it strongly influences the result of each study.
[1] https://en.wikipedia.org/wiki/Recurrent_neural_network
By Giovanni Puccetti e Vito Giordano