



Introduction
Here goes a brand new B4DS notebook!! This week we talk about information extraction from patents. The first thing that comes to mind after reading this is why would someone ever want to find information in patents? They are strangely written, full of technical jargon describing inventions’ details, and legal terms to make them binding. Therefore, where is the point in trying to study such documents?? The point is that there is a large share of information that is only available there. Indeed, patents are the place where several new inventions are first found and they are technical enough to contain very detailed and precise knowledge unavailable elsewhere. Thus, for as hard as it may be, investigating them is worth the effort. Of course one could start reading a lot of documents, but we don’t like doing that, instead we try to use Natural Language Processing (NLP) to reach this goal. In particular, in this notebook we focus on finding users of the invention in patents, this means we try to look for all the times that the text of a patent in some way refers to the person that could possibly be affected by the patented technology. A more formal definition of user can be:
A User is an animated or previously animated entity (human or animal, alive or dead), on which the invention has a positive or negative effect at an unspecified moment.
In general, the identification of certain entities in texts is known as Named Entity Recognition (NER) which can be specified to any type of entity.
How entities are found
Now that we know what we want to do, we need a way to do it. At B4DS we mainly use three ways to find entities in patents:
- Gazettes NER: we use lists of entities for example of users and look for them in the text;
- Rules NER: we use predefined rules to look for entities, an example of rule could be “X plays a guitar” X is a user;
- Machine Learning NER: we use models trained on tagged corpora to extract them from the text, this approach tries to find several rules similar to the ones above by looking at a large amount of text.
The first method is the simplest but also the fastest and allows to find well known entities. The second one needs more care in development but can find several entities and also some that are less expected than the most obvious one, such as player in a card game patent. The last technique relies on good training data and for unusual texts like the ones we use it is harder to use.
Some examples of users we can find in patents:
| …and simple game for golfers of all abilities as well as non-golfers… | Golfers,
Non-golfers |
| …the trainer might hold up an item and prompt the learner to ask the question… | Trainer,
Learner |
| …interactive figure makes the guitar player change his music style… | Guitar Player |
The problems
The hardest step in this task is finding out how well a system performs. This means, in an abstract scenario, we have 1000 patents and we find 1000 users that is a result, but how many users were actually present in the patents we searched? This number is unknown but it dramatically changes the results of what we did. Indeed, if there were 1200 users in total we found a large share, if instead there were 5000 we are not doing well enough and the conclusions we draw from our data are partial and may be incorrect.
One solution is testing the system on a small number of patents, for example 100. An (unlucky) person reads the patents, correctly selects ALL the entities present and then we compare what the person did with the automatic extraction. This gives us a good idea of how well it works.
A second possibility is comparing what we extract with known lists of technologies in the patents, though this approach is less stable and several biases could be hidden in the chosen list. Indeed, since there are patents concerned with all fields of knowledge and technology, any list will incur the risk of being only partially close to the field under examination.
How B4DS extracts entities
After summarizing available solutions to the problem at hand, let’s look at what we tried to do. The rules we described above, an example “X wears something” X is a user, are rather complicated to create, they require a deep knowledge of the field, in our case patents, and even if that is available, the number of such rules is extremely high. However, for atypical texts, such as patents, it can be useful to look at them. We made a hypothesis:
In patents all pronouns that can only refer to humans, e.g. somebody, someone, etc. identify users.
This means that to look for users in patents we can use pronouns to identify sentences similar to those where users appear and look for similar ones in the rest of text. We did this by training classifiers on the sentences we found with users, and then searched how many users we were able to find.
First we inspected the type of words that belonged to sentences where our pronouns are and others where words like device are present. To evaluate the value of this image, we can see how words closer to device are more machine related, whereas those closer to user are more typical to humans, for example feel or desires this means our solution can be useful to find users.
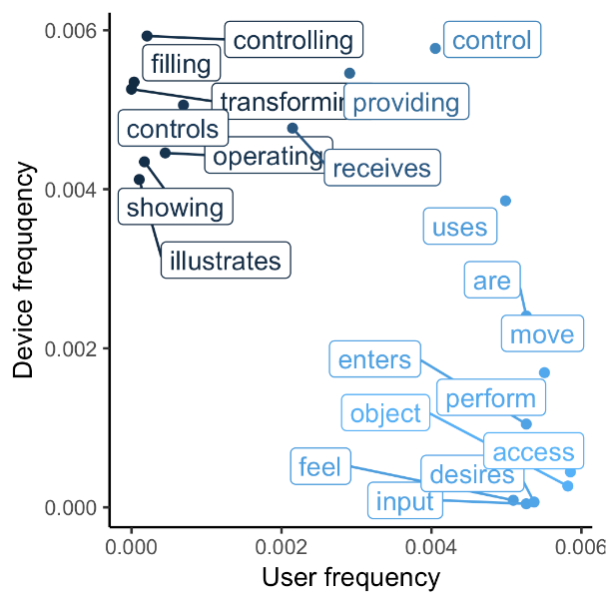
Figure 1. This figure shows the ratio of times each of the words in the plot occurs together with either a user or device, notice how words like “feel” are close to user whereas words like illustrates are close to device.
We then went on to train a classifier on the sentences, this mean we had a computer look at all the words in the sentences that contain a pronoun and memorize the type of words that are present, afterwards we let it look for sentences similar to those in new patents. We managed to reach a precision about 40%, this means 40% of the sentences we found contain a user. This is a good result, considering that users are a rare entity in patents and that our solution does not use any human work. Of course there are several limitations to what we did, the most relevant is that our system still finds several terms that are not users. So, we continue working on it to improve our user finding system.
Moreover, we are trying to find new entities! Now we are starting to look for technologies, a completely different entity from users. In fact, while users are very rare entities, perhaps not so surprisingly, patents are full of technologies, therefore looking for them is a completely different thing.
We’ll tell about that in a new notebook, stay tuned!!
By Giovanni Puccetti e Irene Spada