


Introduction
Natural Language Processing (NLP) is on the rise. Computational Linguistics and Artificial Intelligence are joining their forces fostering breakthrough discovers. While research is focusing on dramatically improve NLP techniques, businesses are considering this technology as a strategic asset. The main role of this radical innovation guided by NLP is played by the large availability of textual data. When it comes to talk about digitalization, especially for businesses, it is important to remember that documents are natively digital and that, consequently, textual data are a primary source of knowledge.
However, when looking to hone a natural language processing task, one of the biggest bottlenecks regards the training of the data. When it comes to real-word applications, such as in specific domains, we face the low-resource data problem. Training the data has two main problems: (i) difficulties in getting a large amount of data and (ii) time-consuming processes on annotating the available data for training and testing.

It has been devoted a large attention in computer science to face these problems. In particular, latest computational advances suggest two approaches to overcome the low-resource data problem:
- Fine-tuning pre-trained language models, such as BERT or GPT-3;
- Leveraging high-quality open repository of data, such as Wikipedia or ConceptNet.
Most of the now available open libraries for computational linguistics offer architectures to develop NLP tools based on one of these two approaches. We now demonstrate how it is possible to leverage Wikipedia to boost the performance of two NLP tasks: Named Entity Recognition and Topic Modeling.
Extract Wikipedia information from sentences
Several tools are available to process information from Wikipedia. For what concerns the automatic processing of textual data, we make use of an open project of spaCy called SpikeX.
SpikeX is a collection of pipes ready to be plugged in a spaCy pipeline, a python library for NLP. SpikeX, developed by an Italian company (Erre Quadro Srl), aims to help in building knowledge extraction tools with almost-zero effort.
SpikeX has two main features:
- Given a Wikipedia page, it extracts all the corresponding categories.
Categories for `Natural_Language_Processing`:
Category:Artificial_intelligence
-> Category:Emerging_technologies
-> Category:Cybernetics
-> Category:Subfields_of_computer_science
-> Category:Computational_neuroscience
-> Category:Futures_studies
-> Category:Cognitive_science
-> Category:Personhood
-> Category:Formal_sciences
Category:Speech_recognition
-> Category:Artificial_intelligence_applications
-> Category:Computational_linguistics
-> Category:Human–computer_interaction
-> Category:Digital_signal_processing
-> Category:Speech
Category:Natural_language_processing
-> Category:Artificial_intelligence_applications
-> Category:Computational_linguistics
Category:Computational_linguistics
-> Category:Computational_social_science
2. Given a sentence, it finds chunks in a text that match Wikipedia page titles.
Elon Musk
('Elon_Musk', 'Elon_musk', 'Elon_Musk_(book)', 'Elon_Musk_(2015_book)', 'Elon_Musk_(2015)', 'Elon_Musk_(biography)', 'Elon_Musk_(2015_biography)', 'Elon_Musk_(Ashlee_Vance)')
------
Elon
('Elon_(Judges)', 'Elon_(name)', 'Elon_(Hebrew_Judge)', 'Elon_(Ilan)', 'Elon_(disambiguation)', 'Elon_(biblical_judge)', 'Elon_(chemical)', 'Elon')
------
Musk
('Musk', 'MuSK', 'Musk_(wine)', 'Musk_(song)', 'Musk_(Tash_Sultana_song)', 'Musk_(disambiguation)')
------
runs
('Runs_(baseball_statistics)', 'Runs', 'Runs_(cricket)', 'Runs_(music)', 'Runs_(baseball)', 'Runs_(Baseball)', 'Runs_(musical)')
------
Tesla Motors
('Tesla_motors', 'Tesla_Motors')
------
Tesla
('Tesla_(band)', 'Tesla_(unit)', 'Tesla_(Czechoslovak_company)', 'Tesla_(crater)', 'Tesla_(microarchitecture)', 'Tesla_(2020_film)', 'Tesla_(car)', 'Tesla_(GPU)', 'TESLA', 'Tesla_(physicist)', 'Tesla_(group)', 'Tesla_(opera)', 'Tesla_(Bleach)', 'Tesla_(company)', 'Tesla_(disambiguation)', 'Tesla_(2016_film)', 'TESLA_(Czechoslovak_company)', 'Tesla_(unit_of_measure)', 'Tesla_(vehicles)', 'Tesla_(vehicle)', 'Tesla_(film)', 'Tesla_(album)', 'Tesla_(Flux_Pavilion_album)', 'Tesla_(surname)', 'Tesla')
------
Motors ('Motors')
As we can see, in the first example, SpikeX extracts all the categories whose Wikipedia page “Natural_language_processing” belongs to. For example, “Natural_language_processing” belongs to the categories of “Artificial_intelligence”, “Speech_Recognition” and “Computational_linguistics”. The tree-structure of the Wiki categories can be further explored with a deeper level of inspection.
In the second example, for the sentence “Elon Musk runs Tesla Motors”, SpikeX extracts all the pages of the sentence that are likely to have a page on Wikipedia.
We now see how these two processing features can be used to perform Named Entity Recognition and Topic Modeling.
Named Entity Recognition
Named Entity Recognition (NER) is a NLP task that seeks to locate and classify entities mentioned in text into pre-defined categories (such as person names, organizations, locations, etc…). Different approaches deal with this task achieving high accuracy: rule-based system, approaches that train deep neural networks or approaches that fine-rune pre-trained language models. Spacy, for example, embeds a pre-trained Named Entity Recognition system that is able to identify common categories from text.
We now approach the building of a NER system able to identify pieces of text that belong to a certain Wikipedia category. Let us consider the following example sentence:
“Named Entity Recognition and Topic Modeling are two tasks of Natural Language Processing”
This sentence potentially contains three entities: “Named Entity Recognition,”, “Topic Modeling” and “Natural Language Processing”. These three entities have their respective Wikipedia pages that belong to certain Categories.

In this picture we can see how the different Categories are spread among the three entities. In this case, Categories can be seen as the labels of the entities that we want to extract from the text. We can now exploit the two features of SpikeX to build a custom NER system that takes in input two variables: the (i) text of the sentence and the (ii) Category we want to detect.

Named Entity Recognition - COMPUTATIONAL LINGUISTIC
Topic Modeling - COMPUTATIONAL LINGUISTIC
Natural Language Processing - COMPUTATIONAL LINGUISTIC
Defining categories of wikipedia as labels for NER tasks gives the possibility to define a NER system avoiding the data training problem. A further example is shown by using displacy to represent the extracted entities with our NER system based on Wikipedia categories.

In this example, the categories “Programming Language” and “Computational Linguistics” are given as input and then searched in the text.
Topic Modelling
When it comes to talk about Topic Modeling, we usually refer to a NLP tool that is able to discover the “hidden semantic structures” of a text body. Recently, it has been discussed that “the very definition of topic, for the purpose of automatic text analysis, is somewhat contingent on the method being employed” [1]. Latent Dirichlet Allocation (LDA) is the popular topic modeling method that uses a probabilistic model to extract topics among sets of documents. Another famous approach is TextRank, a method that uses network analysis to detect topics within a single document. Recently, advanced researches in NLP introduced also methods that are able to extract topics at sentence level. One example are the Semantic Hypergraphs, a “novel technique combines the strengths of Machine Learning and symbolic approaches to infer topics from the meaning of sentences” [1].
We now see how using Wikipedia is possible to perform Topic Modeling at sentence and document level.
Let us consider the following text from the patent US20130097769A1.
Encapsulated protective suits may be worn in contaminated areas to protect the wearer of the suit. For example, workers may wear an encapsulated protective suit while working inside of a nuclear powered electrical generating plant or in the presence of radioactive materials. An encapsulated protective suit may be a one-time use type of system, wherein after a single use the suit is disposed of. An encapsulated protective suit may receive breathing air during normal operating conditions via an external air flow hose connected to the suit. The air may be supplied, for example, by a power air purifying respirator (PAPR) that may be carried by the user.
Sentence: Encapsulated protective suits may be worn in contaminated areas to protect the wearer of the suit. Topics in the sentence: Safety -> 1 Euthenics -> 1 ----Sentence: For example, workers may wear an encapsulated protective suit while working inside of a nuclear powered electrical generating plant or in the presence of radioactive materials. Topics in the sentence: Safety -> 1 Euthenics -> 1 Electricity -> 1 Electromagnetism -> 1 Locale_(geographic) -> 1 Electric_power_generation -> 1 Power_stations -> 1 Infrastructure -> 1 Energy_conversion -> 1 Chemistry -> 1 Radioactivity -> 1 ---- Sentence: An encapsulated protective suit may be a one-time use type of system, wherein after a single use the suit is disposed of. Topics in the sentence: Safety -> 1 Euthenics -> 1 Transportation_planning -> 1 Feminist_economics -> 1 Schools_of_economic_thought -> 1 Land_management -> 1 Architecture -> 1 Planning -> 1 Transport -> 1 Feminism -> 1 Urban_planning -> 1 Feminist_theory -> 1 Urbanization -> 1 Spatial_planning -> 1 Social_sciences -> 1 ----Sentence: An encapsulated protective suit may receive breathing air during normal operating conditions via an external air flow hose connected to the suit. Topics in the sentence: Safety -> 1 Euthenics -> 1 Chemical_industry -> 1 Gases -> 1 Industrial_gases -> 1 Breathing_gases -> 1 Diving_equipment -> 1 Respiration -> 1 Electromechanical_engineering -> 1 Heat_transfer -> 1 Home_appliances -> 1 Engineering_disciplines -> 1 Automation -> 1 Building_engineering -> 1 Temperature -> 1 Heating,_ventilation,_and_air_conditioning -> 1 ---- Sentence: The air may be supplied, for example, by a power air purifying respirator (PAPR) that may be carried by the user.Topics in the sentence: Personal_protective_equipment -> 1 Air_filters -> 1 Respirators -> 1 Protective_gear -> 1 ----
Each sentence of the patent text is processed with SpikeX and Categories are extracted from the corresponding Wikipedia pages detected in the sentence. We consider topics as the Categories of Wikipedia. In this way we have a first naive detection of topics. This method, differently from Semantic Hypergraphs, Text Rank or LDA, finds labels for the topic of the sentence without referring directly to terms. The label of the topics extracted refer to the Categories of the Wikipedia pages matched by SpikeX. If we use this method aggregating the topics for each sentence we have a better representation for the entire document.
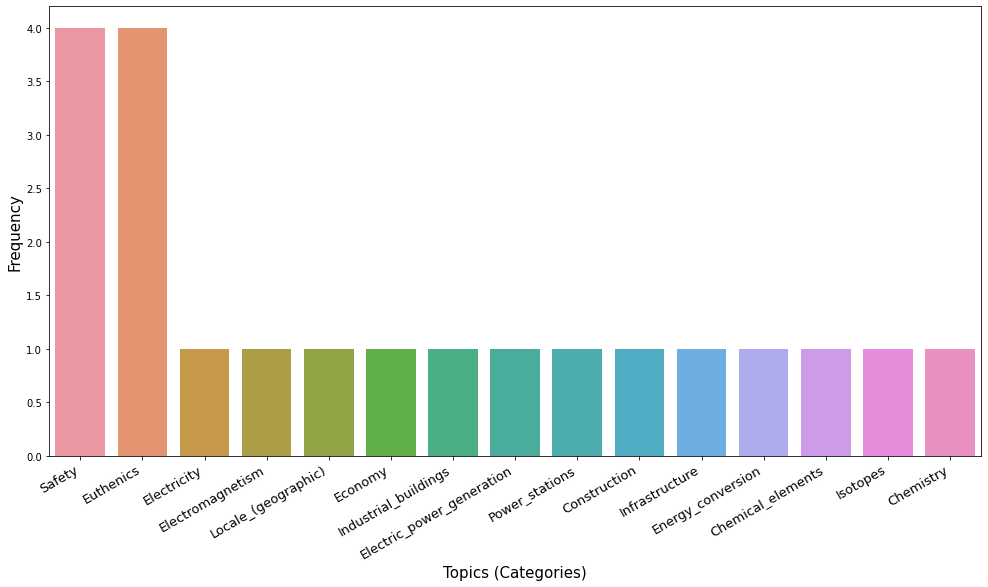
Raking the frequency of categories among the sentences enables a wider view of the topic distribution of the text. “Safety” and “Euthenics” appear more frequently than the other categories.
We now use the entire patent text (available in Google Patent) to find the categorical distribution.
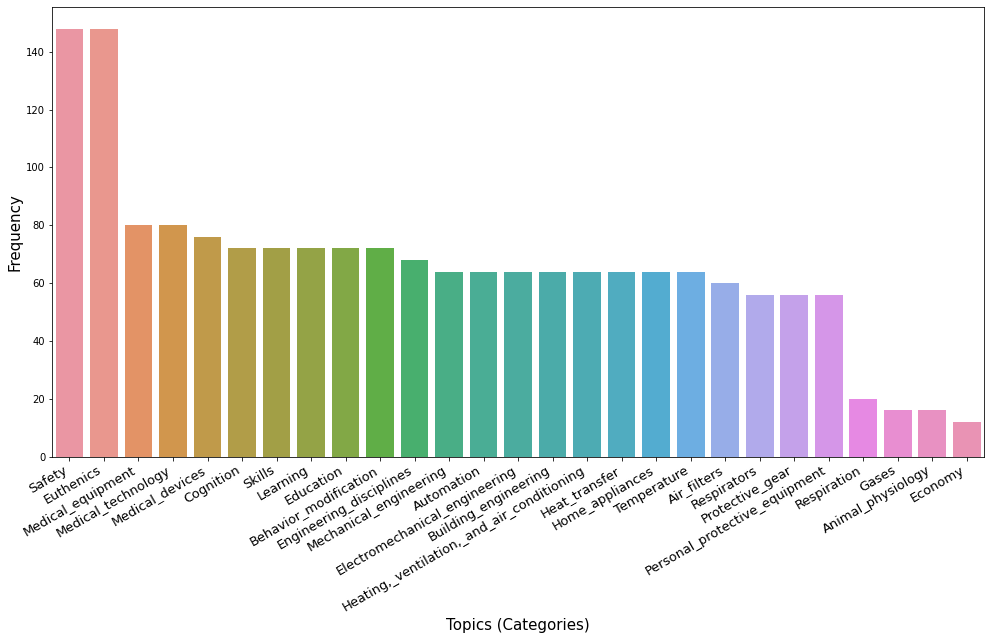
As we can see, we have an automatic detection of the topics (or Categories) the entire document (a patent, in this case). Looking to the top 5 Categories we can infer what the patent is about. This has been done without any pre-training tasks.
Conclusions
Wikipedia has been exploited as source of knowledge for more than a decade and has been used repeatedly in a variety of applications: text annotation, categorization, indexing, clustering, searching and automatic taxonomies generation. The structure of Wikipedia has in fact a number of useful features that make it a good candidate for these applications.
This post demonstrates how simple tasks of NLP can be improved by using this powerful source. However, it is not claimed that this approach outperforms other state-of-art approaches. The typical measures of precision and recall, that assess the accuracy of NLP tasks, are not shown in this post.
Moreover, this approach has advantages and drawbacks. The main advantage regards the avoidance of training and consequently reduction of time-consuming annotation tasks. It is possible to see Wikipedia as an huge training set with contributors coming worldwide. This is true for supervised (such as NER) and unsupervised tasks (such as Topic Modeling). The drawback of this approach is twofold. First, Wikipedia is a public service that serves as a knowledge base with contributions from experts and non-experts. Second, as we can see from the topic modeling results, the ambiguity of natural language can lead to biased performance. Word-sense disambiguation and non-expert driven curation of the data clearly affects the reliability of the whole system.
There is a large room for improvement, however. Considering Wikipedia as a large open Knowledge Base for NLP tasks is aligned the new upcoming paradigm shift: the so-called Artificial general intelligence (AGI), the hypothetical ability of a system to understand or learn any intellectual task that a human being can.
[1] Menezes, Telmo, and Camille Roth. “Semantic hypergraphs.” arXiv preprint arXiv:1908.10784 (2019).
We would like to thank Erre Quadro Srl and, in particular Paolo Arduin, that developed the project SpikeX making it of open access.
This post is originally published in Towards Data Science at the following link https://towardsdatascience.com/boosting-natural-language-processing-with-wikipedia-b779103ba396.